-
Merging Realtime Segments in Apache Druid
So, you want your realtime analytical queries to be really fast, and that’s why you selected Apache Druid! Today, let’s have a look at another aspect of how Druid achieves its amazing performance.
-
Analyzing GitHub Stars with Imply Polaris
Jul 12, 2023 • blog, druid, imply, polaris, sql, datamodeling, tutorial

-
Indexes in Apache Druid
If you come from a traditional database background, you are probably used to creating and maintaining indexes on most of your data. In a relational database, indexes can speed up queries but at a cost of slower data insertion.
-
New in Druid 26: Data Provenance Tracking with Kafka Headers, Automatically

-
Overlaying Multiple Metrics in Imply Pivot
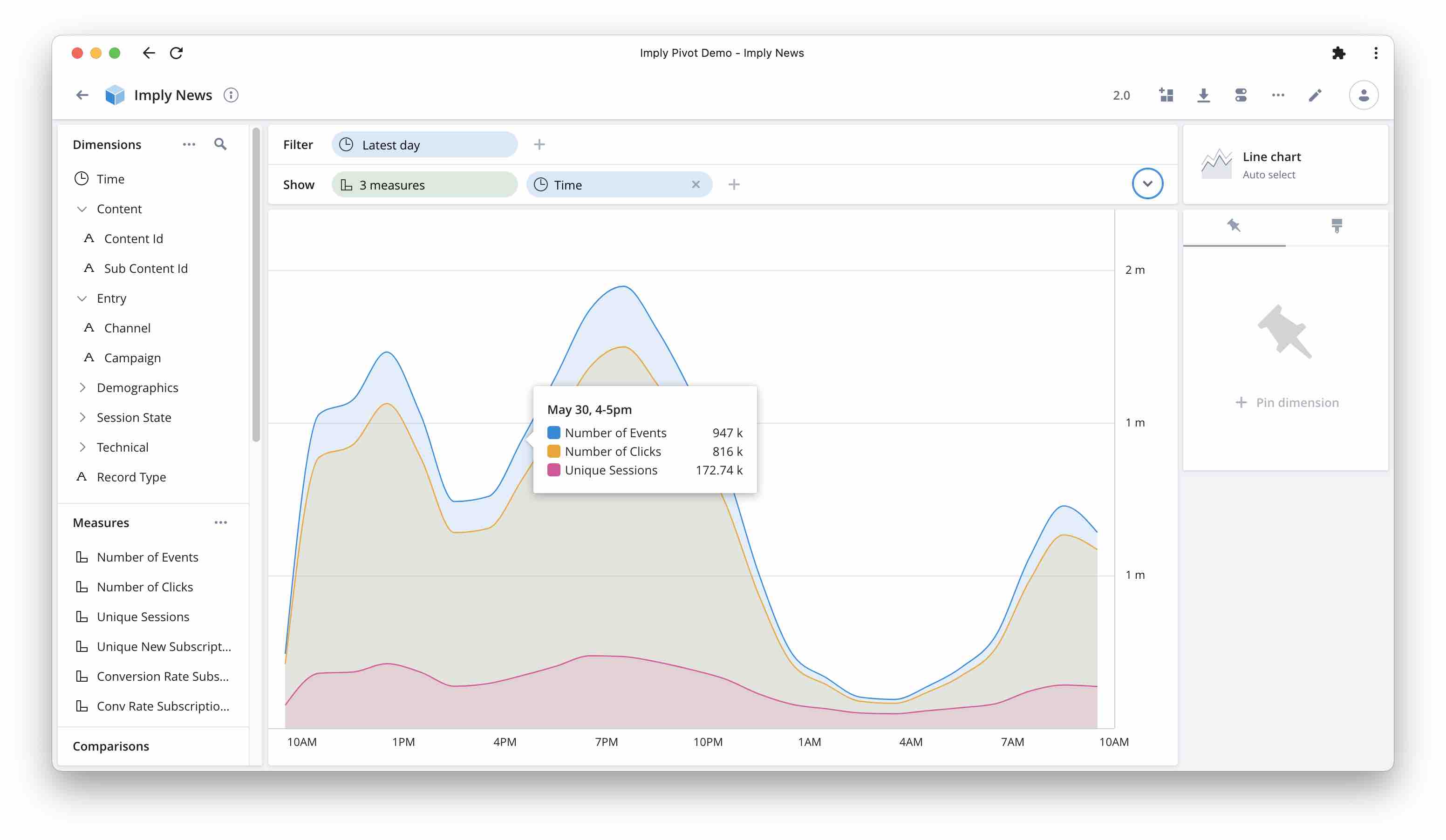
-
Merging Realtime Segments in Apache Druid
So, you want your realtime analytical queries to be really fast, and that’s why you selected Apache Druid! Today, let’s have a look at another aspect of how Druid achieves its amazing performance.
-
Analyzing GitHub Stars with Imply Polaris
-
Indexes in Apache Druid
If you come from a traditional database background, you are probably used to creating and maintaining indexes on most of your data. In a relational database, indexes can speed up queries but at a cost of slower data insertion.
-
New in Druid 26: Data Provenance Tracking with Kafka Headers, Automatically
-
Overlaying Multiple Metrics in Imply Pivot