-
Getting My Graphics Smaller - Experimenting with AVIF
Nov 15, 2021 • blog, image-compression
I thought I was going to move from using JPEG images to AVIF in my blog.
-
Fun with Spatial Dimensions in Apache Druid
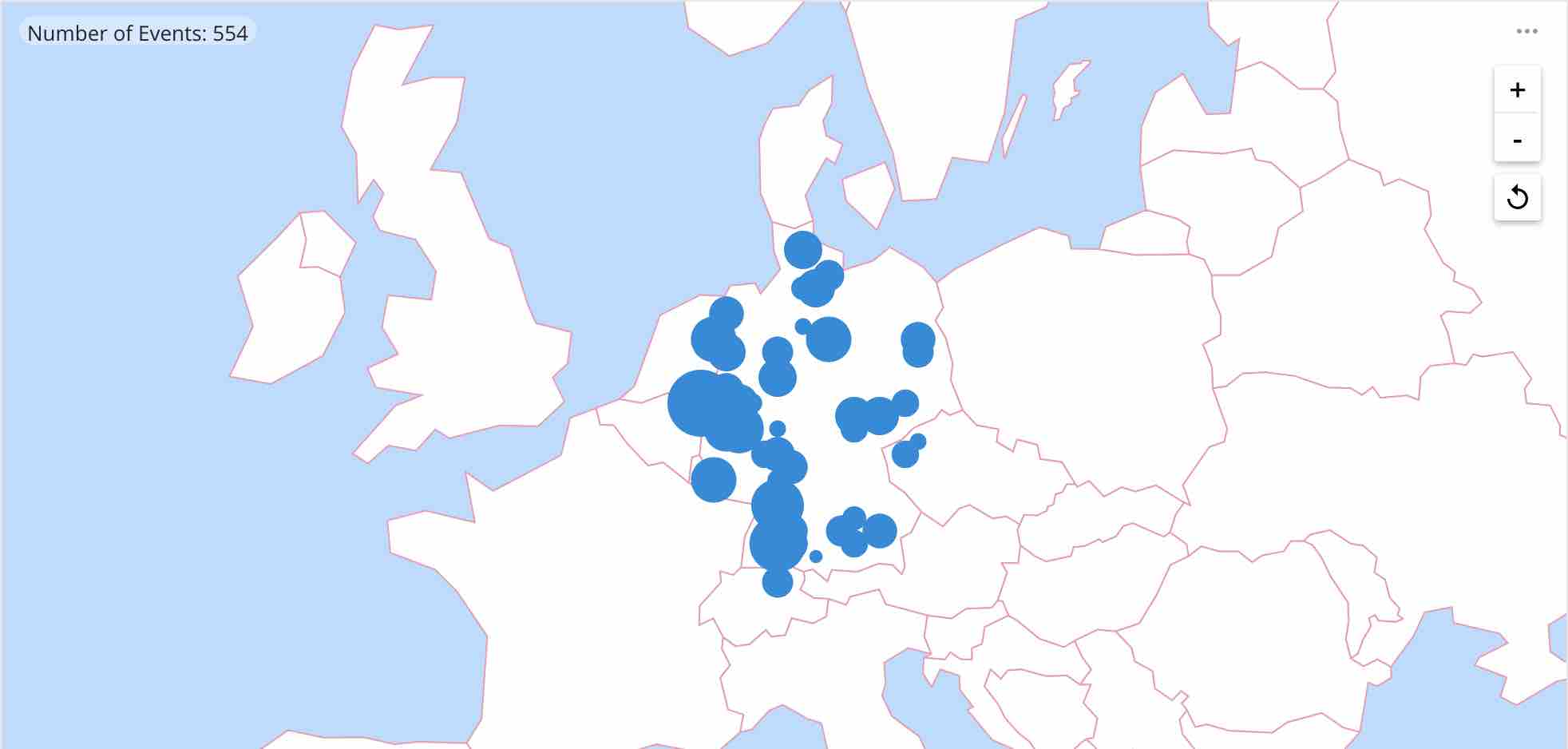
-
Reading Avro Streams from Confluent Cloud into Apache Druid
Oct 19, 2021 • blog, imply, druid, confluent, kafka, eventstreaming, tutorial
Today I am going to show how to get AVRO data from a schema aware Confluent Cloud cluster into Apache Druid. Use the Druid 0.22 micro-quickstart setup for this exercise.
-
Druid Data Modeling Special: Lookups and Multi-Value Dimensions
The other day, Peter Marshall brought up a question: Do lookups work with multi-value dimensions in Druid? Spoiler alert: They do, in fact! But let’s first take a quick look at what lookups are.
-
Advanced Regex Exclude Filters in Imply Pivot
Oct 10, 2021 • blog, apache, druid, imply, tutorial, pivot, regex
In this short post I want to take a closer look at Imply Pivot and how to address a common scenario for analytics: Let’s assume we want to filter on a dimension value, but we want to exclude rather than include a set of dimension values.
-
Getting My Graphics Smaller - Experimenting with AVIF
I thought I was going to move from using JPEG images to AVIF in my blog.
-
Fun with Spatial Dimensions in Apache Druid
-
Reading Avro Streams from Confluent Cloud into Apache Druid
Today I am going to show how to get AVRO data from a schema aware Confluent Cloud cluster into Apache Druid. Use the Druid 0.22 micro-quickstart setup for this exercise.
-
Druid Data Modeling Special: Lookups and Multi-Value Dimensions
The other day, Peter Marshall brought up a question: Do lookups work with multi-value dimensions in Druid? Spoiler alert: They do, in fact! But let’s first take a quick look at what lookups are.
-
Advanced Regex Exclude Filters in Imply Pivot
In this short post I want to take a closer look at Imply Pivot and how to address a common scenario for analytics: Let’s assume we want to filter on a dimension value, but we want to exclude rather than include a set of dimension values.